Métodos adaptativos de compresión
Hola, esta entrada trata sobre los métodos adaptativos de compresión de datos, para esta actividad se nos encargó inventar, implementar y evaluar nuestro propio método adaptativo de compresión.
Como ya lo había comentado en mi post anterior (no está de más); la compresión de información es el proceso de codificar de una manera efectiva con el objetivo de reducir el número de bits necesarios para representar cierta información.
En la tarea pasada vimos un algoritmo que cumple con las tareas antes mencionadas, pero esta vez se nos pidió desarrollar un método de compresión dinámico o adaptativo.
Esto quiere decir que no hay un cálculo de frecuencia de los símbolos usados (como la pasada tarea en codificación de Huffman), estos métodos adaptativos son principalmente usados en el streaming de información ya que se adaptan a los cambios que se localizan en las características de los datos.
Debo mencionar que a mi no se me ocurrió ningún algoritmo donde pudiera implementar este tipo de método, sin embargo; en previas lecturas cuando realicé la tarea anterior (Huffman) conocí algunos tipos de compresión adaptativos, por ejemplo el LZW (Lempel-Ziv-Welsh) que es un sistema adaptativo del LZ (de Lempel y Jacob Ziv).
Con el sistema LZW es posible crear "al vuelo" y en una sola pasada un diccionario de cadenas que se encuentren dentro del texto a comprimir mientras al mismo tiempo se procede a su codificación.
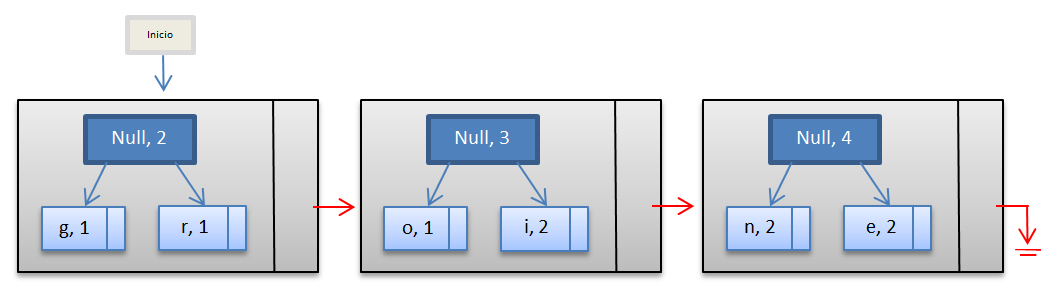
Para explicar de una manera práctica este método podemos comenzar con un diccionario de 3 caracteres, cada uno con una codificación del 1 al 3.

Tomemos de entrada la siguiente cadena: ABABBABCABABBA
El algoritmo de compresión LZW hace lo siguiente:

Toma el primer caracter de entrada (s), luego toma el que le sigue(c), la salida (output), que será el código que representará a la cadena original, será el equivalente al valor del código que tiene el caracter s en nuestro diccionario, luego el código para nuestro nuevo string va aumentando una unidad y el nuevo string se guarda en nuestro diccionario (junto con su valor de código) para poder contar con patrones que luego se puedan repetir. El método hace lo mismo hasta que el contenido de nuestro mensaje sea nulo.
Para la descompresión podemos pintar una tabla similar, porque prácticamente se sigue el mismo proceso:

Noten que ahora la columna de output es la cadena original que introducimos.
Bien, yo codifiqué en python este método:
En algunas de las notas que leí, mencionan que la relación de compresión de este método es de aproximadamente de un tercio del archivo; también mencionan que se utiliza en formatos universales como el GIF o el TIFF.
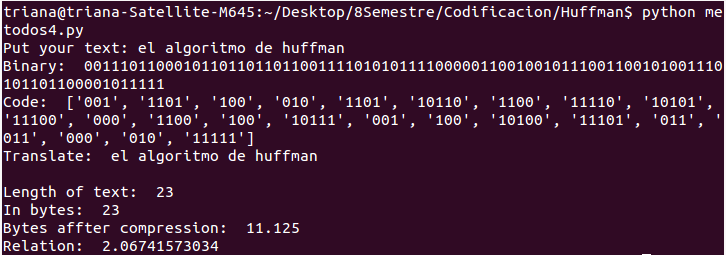
Yo realicé unas sencillas pruebas midiendo la proporción de compresión:
Prueba 1

Yo realicé unas sencillas pruebas midiendo la proporción de compresión:
Prueba 1

Prueba 2

Prueba 3

Prueba 4

Conclusiones
Bueno, como lo mencioné antes, en algunas notas mencionan que la relación de compresión es de aproximádamente un tercio del archivo. En mis pruebas lo máximo que obtuve fue comprimir a más de la mitad y seguía conforme iba aumentando el largo del mensaje original.
Una de las desventajas es que hay que agregar al diccionario los caracteres que vas a usar, y haciendo un diagnóstico más detallado nos podemos dar cuenta que muchos de los caracteres que agregamos ni siquiera se usan, ocupando demasiada memoria de una manera inecesaria en el diccionario.
Mi repositorio de git: https://github.com/eddypre/M-todosCodificaci-n
Bibliografía:
Compression adaptive
http://elisa.dyndns-web.com/~elisa/teaching/comp/info/adaptive.pdf
Bibliografía:
Compression adaptive
http://elisa.dyndns-web.com/~elisa/teaching/comp/info/adaptive.pdf
Cualquier duda o aclaración pueden ponerla en los comentarios.
Saludos a todos!